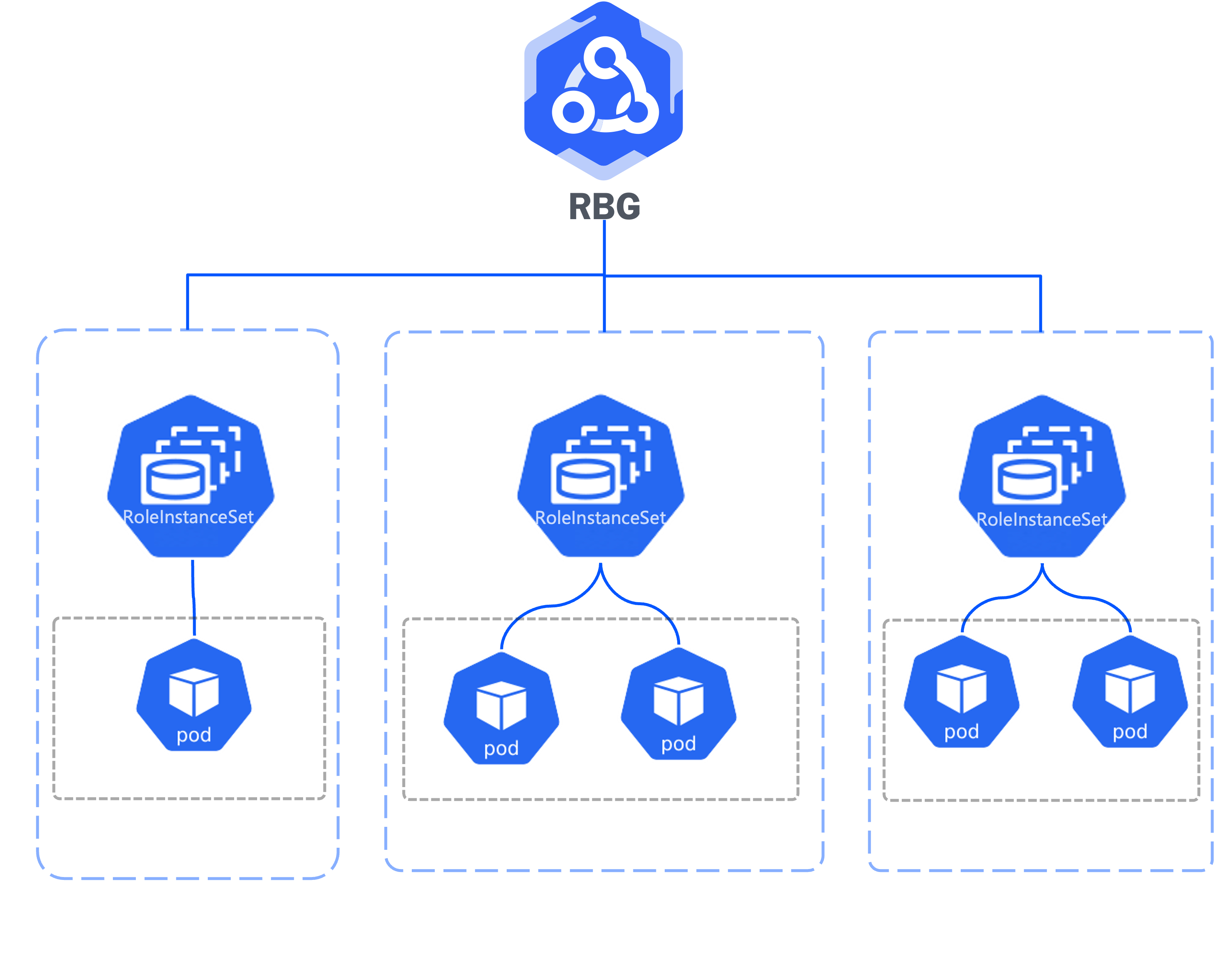
RoleBasedGroup
Kubernetes-native
LLM Inference Orchestration
Production-grade deployment for multi-role AI workloads, orchestrating distributed, stateful inference workloads with seamless role collaboration.
Any Inference Engine × Any Architecture
PD Disaggregated · EPD Disaggregated · AF Disaggregated · Tensor Parallel
All with a single declarative API (v1alpha2).
apiVersion: workloads.x-k8s.io/v1alpha2
kind: RoleBasedGroup
metadata:
name: llm-inference
spec:
roles:
- name: router
replicas: 1
standalonePattern: ...
- name: prefill
replicas: 2
leaderWorkerPattern:
size: 4 # 1 leader + 3 workers
- name: decode
replicas: 4
dependencies: ["prefill"]
leaderWorkerPattern:
size: 2Built for Production LLM Serving
Everything you need to run distributed inference at scale, with the simplicity of native Kubernetes APIs (v1alpha2).
Multi-Role Orchestration
Define complex topologies with gateway, router, prefill, and decode roles. Use standalonePattern for single-pod instances or leaderWorkerPattern for distributed tensor parallelism.
Learn moreExclusive Topology Scheduling
Pods of different roles are automatically scheduled on different nodes or topology zones using the exclusive-topology annotation for isolation.
Learn moreInplace Update
Efficient inplace update mechanism that minimizes disruption during configuration changes. Update pod specifications without recreating entire role groups.
Learn moreCoordinated Updates
Use CoordinatedPolicy CRD for coordinated rolling updates. maxSkew ensures roles stay within 1% progress difference during updates.
Learn moreIndependently AutoScaling
Each role can scale independently based on its own metrics. Flexible HPA integration via scalingAdapter for per-role autoscaling policies.
Learn morePre-Warmup
Pre-warmup mechanism for faster service initialization. Roles can be pre-provisioned and warmed up before serving requests, reducing cold start latency.
Learn moreEcosystem Integrations
RBG integrates with leading AI inference runtimes and frameworks, providing a complete solution for production LLM serving.
Get Started in Minutes
Deploy your first inference service with just a few commands. RBG integrates seamlessly with your existing Kubernetes workflow.
# Install RBG controller
kubectl apply --server-side -f https://raw.githubusercontent.com/sgl-project/rbg/main/deploy/kubectl/manifests.yaml
# Wait for controller to be ready
kubectl wait deploy/rbgs-controller-manager -n rbgs-system \
--for=condition=available --timeout=5m
Deployment Patterns
From single-node development to production-grade disaggregated serving, RBG supports all inference topologies with native Kubernetes APIs.
Aggregated Standalone
Deploy LLM inference on a single node when the model fits in one node's memory. The simplest setup for development and testing.
Use case: Models under 70B parameters on single or multi-GPU nodes
View full exampleapiVersion: workloads.x-k8s.io/v1alpha2
kind: RoleBasedGroup
metadata:
name: sglang-agg-inference
spec:
roles:
- name: backend
replicas: 1
scalingAdapter:
enable: true
rolloutStrategy:
type: RollingUpdate
rollingUpdate:
type: InPlaceIfPossible
standalonePattern:
template:
spec:
containers:
- name: backend
image: lmsysorg/sglang:v0.5.9
command:
- python3
- -m
- sglang.launch_server
- --model-path
- "Qwen/Qwen3-0.6B"
- --port
- "8001"
- --tp-size
- "1"
resources:
limits:
nvidia.com/gpu: "1"How It Works
RBG treats your inference service as a coordinated organism, managing roles, dependencies, and topology as a single unit.
RBG in ACK Serving Stack
RoleBasedGroup is a core component of Alibaba Cloud's ACK Serving Stack, providing the orchestration layer for production-grade LLM inference services.

Native Integration
Seamlessly integrated with ACK's container runtime and GPU management capabilities.
Performance Optimized
Leverages ACK's high-performance network and storage stack for optimal inference throughput.
Enterprise Ready
Built on ACK's enterprise-grade security, observability, and multi-cluster capabilities.
Use Cases
RBG powers production LLM inference across diverse industries and use scenarios.
(Content to be added)
Cloud Service Providers
Deploy and manage large-scale LLM inference services for cloud customers. Scale from hundreds to thousands of instances with coordinated updates.
Enterprise AI Platforms
Run private LLM inference infrastructure with topology-aware placement for optimal GPU utilization and minimal latency.
AI Research Labs
Experiment with novel inference architectures like PD-disaggregation. Quickly iterate on multi-role topologies for research.
Model Hosting Services
Host multiple LLM models with isolated deployments. RoleBasedGroupSet enables managing identical inference clusters.
How to Contribute
We welcome contributions from the community! Whether you're fixing a bug, adding a feature, or improving documentation, your help makes RBG better.
Create a Branch
Create a feature branch for your changes. Follow the naming convention: feature/your-feature-name.
git checkout -b feature/your-feature-nameMake Changes
Implement your feature or fix. Write clean, well-documented code following our style guidelines.
Write Tests
Add tests for your changes. Ensure all existing tests pass before submitting.
Submit PR
Push your changes and create a Pull Request. Include a clear description of your changes.
Learn more