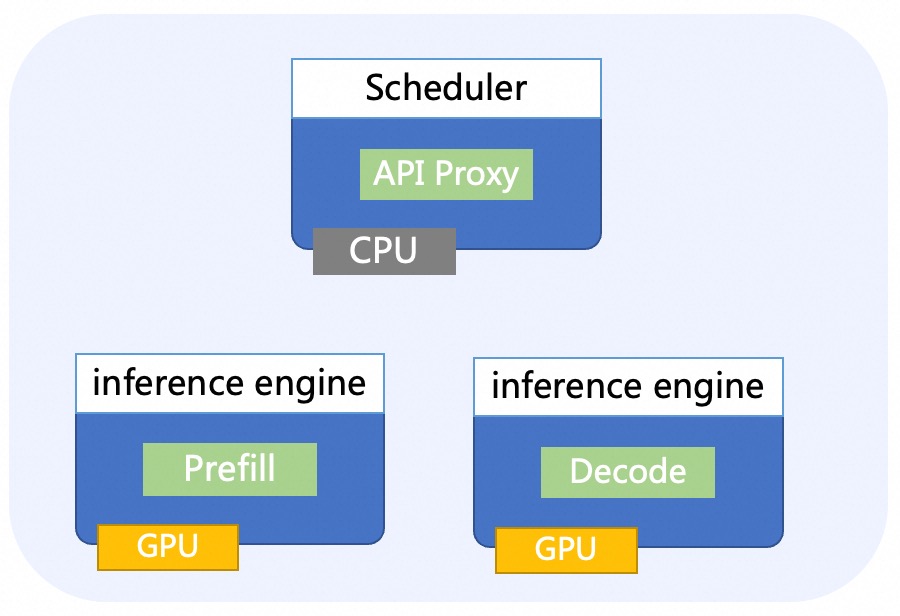
Architecture
RBG treats "Role" as the atomic unit for scheduling orchestration, while establishing configurable relationships between different roles. It views a single inference service as a topological, stateful, and collaborative "Role Organism," rather than an isolated collection of Deployments.
The SCOPE Framework
Based on this philosophy, RBG has built the five core capabilities:
🔁 Stable
Topology-aware deterministic operations with unique RoleID injection and minimal replacement domain principles.
🤝 Coordination
Cross-role policy engine supporting deployment pairing, coordinated upgrades, linked recovery, and coordinated scaling.
🧭 Orchestration
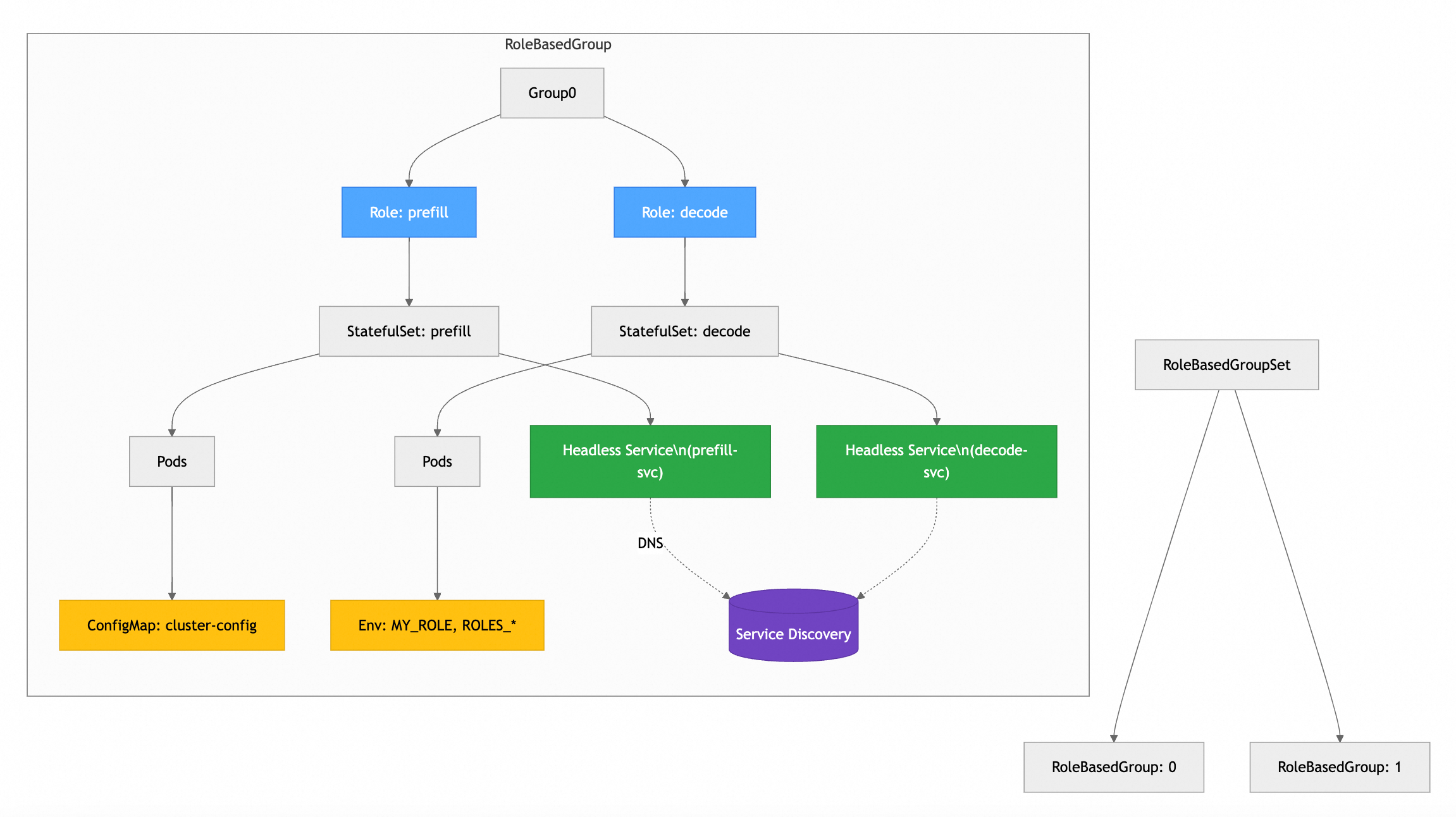
Defines role dependencies and precise startup sequences within a RoleBasedGroup. Topology self-aware service discovery - injects complete role topology into Pods, eliminating external service dependencies.
⚡ Performance
Topology-aware placement with hardware affinity (GPU-NVLink > PCIe > RDMA > VPC) and role affinity scheduling.
🧩 Extensible
Future-proof deployment abstraction using declarative APIs and plugin mechanisms to adapt new architectures in weeks.
Architecture Diagram
Deployment Patterns
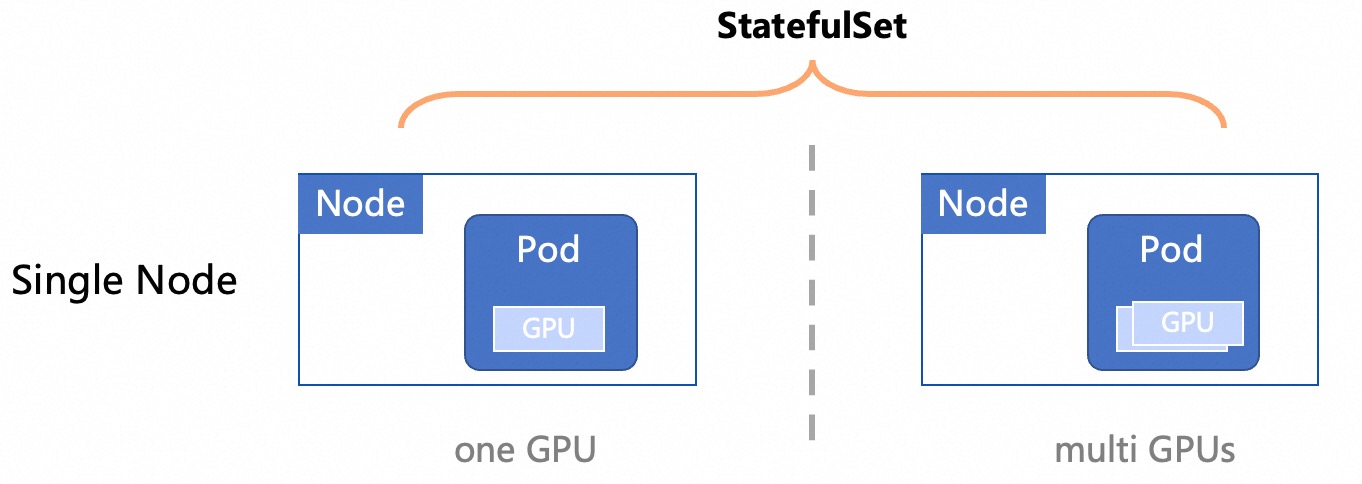
Single Node
When the model is small enough that a single Kubernetes Node can load all model files, you can deploy the LLM inference service on a single node.
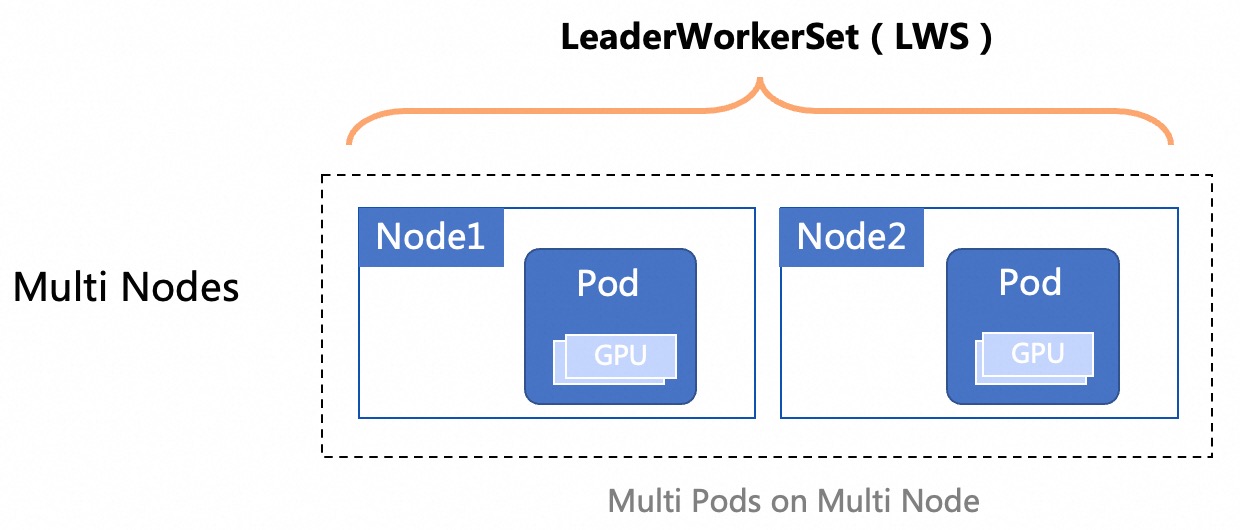
Multi Node
When the model is too large for a single Node to load all files, use multi-node distributed inference.
PD Disaggregated
Disaggregating the prefill and decoding computation improves the performance of large language models (LLMs) serving.